3 lattice
El paquete lattice es una herramienta poderosa para la visualización de datos multivariantes en R. Desarrollado por Deepayan Sarkar, lattice está basado en el concepto de gráficos en trellis 7, que facilita la visualización de relaciones complejas entre múltiples variables mediante la creación de gráficos condicionados. Esto es especialmente útil en análisis exploratorios de datos, donde es crucial comprender las interacciones y patrones en conjuntos de datos grandes y complejos.
3.1 Características Principales
- Gráficos Condicionados: lattice permite crear gráficos que muestran relaciones entre variables condicionadas a los valores de otras variables. Esto facilita la visualización de patrones en subgrupos de datos.
- Paneles Múltiples: Los gráficos pueden ser divididos en paneles múltiples, cada uno mostrando una porción diferente del conjunto de datos, lo que permite una comparación visual directa entre diferentes subgrupos.
- Fórmulas: Utiliza una fórmula para especificar las relaciones entre las variables que se van a graficar, proporcionando una sintaxis clara y concisa.
- Temas Personalizables: lattice permite la personalización de temas gráficos, incluyendo colores, tamaños y tipos de letra, lo que facilita la creación de visualizaciones estéticamente agradables.
- Integración con el Modelo de Trellis: La integración con el modelo de Trellis permite la creación de gráficos consistentes y bien organizados.
Lo primero escribimos unas líneas de código que verifiquen si el paquete está instalado, y en caso negativo lo instalen. Posteriormente lo cargamos:
# Verificar si el paquete está instalado
if (!require("lattice")) install.packages("lattice")
# Cargar paquete
library(lattice)Como se comentaba, la principal funcionalidad de este paquete es que permite diferenciar cualquier tipo de gráfico (Diagrama de dispersión, Histograma,… ) a partir de una variable categórica mostrando diferentes gráficos o superpuestos en uno mismo. Para ilustrar lo ventajoso de este gráfico se expondrá un ejemplo:
3.2 Datos de ejemplo
Vamos a usar el conjunto de datos mtcars que pertenece al paquete datasets el cual fue elaborado para la revista Motor Trend US en 1974 y que contiene el consumo de combustible y 10 aspectos relacionados con el diseño y rendimiento para 32 coches distintos. Es un dataset muy usado en el aprendizaje de R y que permite ejemplificar diversas técnicas estadísticas.
Variables del dataset mtcars:
- mpg: Medida autonomía del coche. Millas recorridas por galón de combustible (miles per gallon)
- cyl: Número de cilindros
- disp: Desplazamiento (pulgadas cúbicas)
- hp: Potencia (caballos de fuerza)
- drat: Relación del eje trasero
- wt: Peso del auto (miles de libras)
- qsec: Tiempo de 1/4 de milla (en segundos)
- vs: Tipo de motor (0 = V-shaped, 1 = Straight)
- am: Tipo de transmisión (0 = Automática, 1 = Manual)
- gear: Número de marchas
- carb: Número de carburadores
data <- mtcars
data$gear <- factor(data$gear, levels = c(3, 4, 5))
data$cyl <- factor(data$cyl, levels = c(4, 6, 8))
head(data)## mpg cyl disp hp drat wt qsec vs am gear carb
## Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
## Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
## Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
## Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
## Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
## Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1Suponer que se desea mostrar la relación entre mpg y hp para ver si hay relación entre la velocidad y la potencia del coche. Por ello, parece razonable realizar un gráfico tipo:
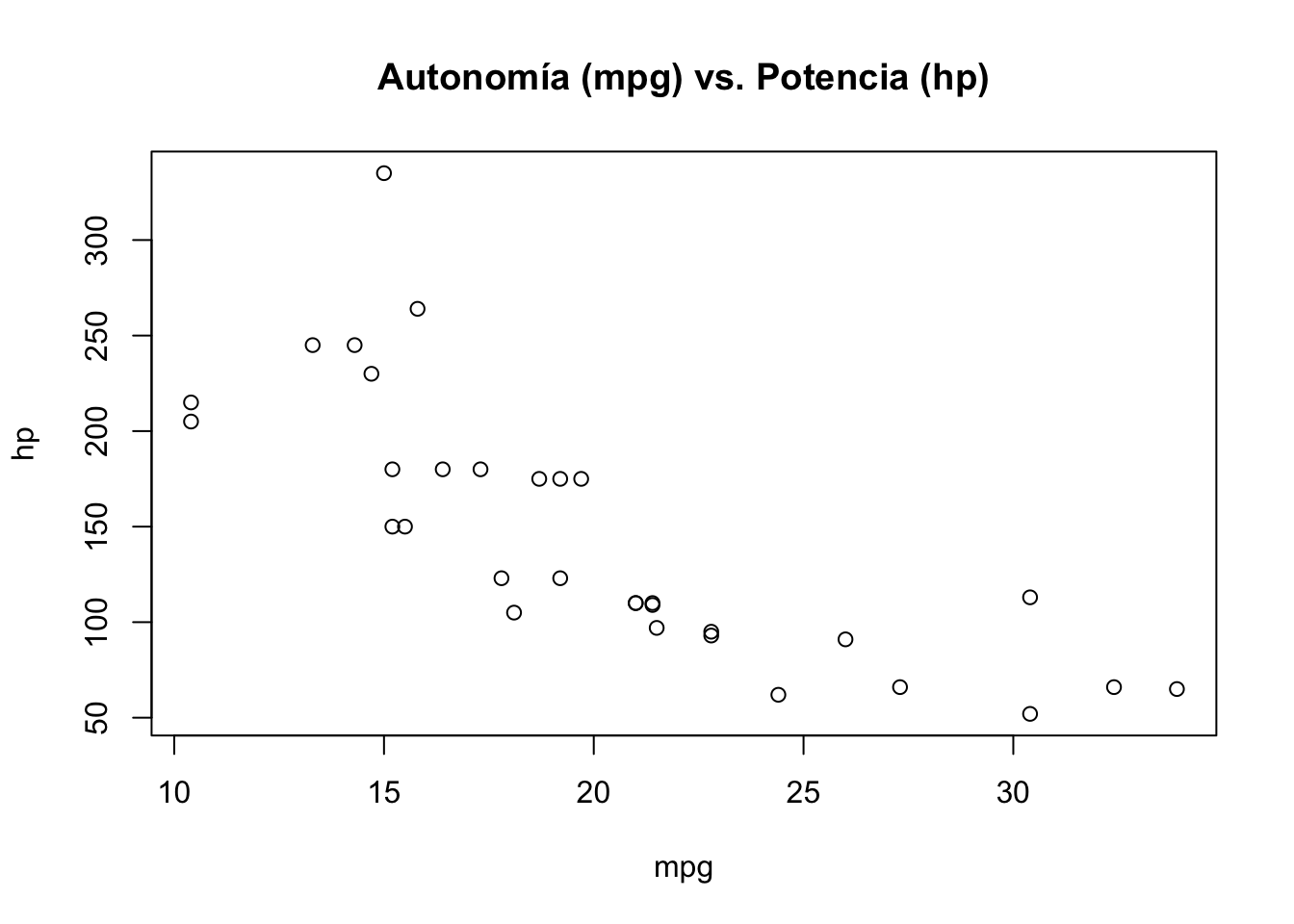
FIGURA 3.1: Gráfico de dispersión de potencia y auonomía de los automóviles.
Se observa que a medida que aumenta la potencia del motor (hp), disminuye el consumo de combustible medido en millas por galón (mpg), lo cual tiene sentido ya que a mayor potencia de un coche, más combustible se espera que gaste, y por tanto menor autonomía tendrá.
Ahora suponer que queremos hacer distinciones en función del número de cilindros del coche, es decir, el mismo gráfico de dispersión condicionado por el número de cilindros:
plot(hp ~ mpg, col = factor(cyl), data = data, main = " Autonomía (mpg) vs. Potencia (hp) ")
# Legend
legend("topright",
title = "Cilindros",
legend = levels(factor(data$cyl)),
pch = 19,
col = factor(levels(factor(data$cyl)))
)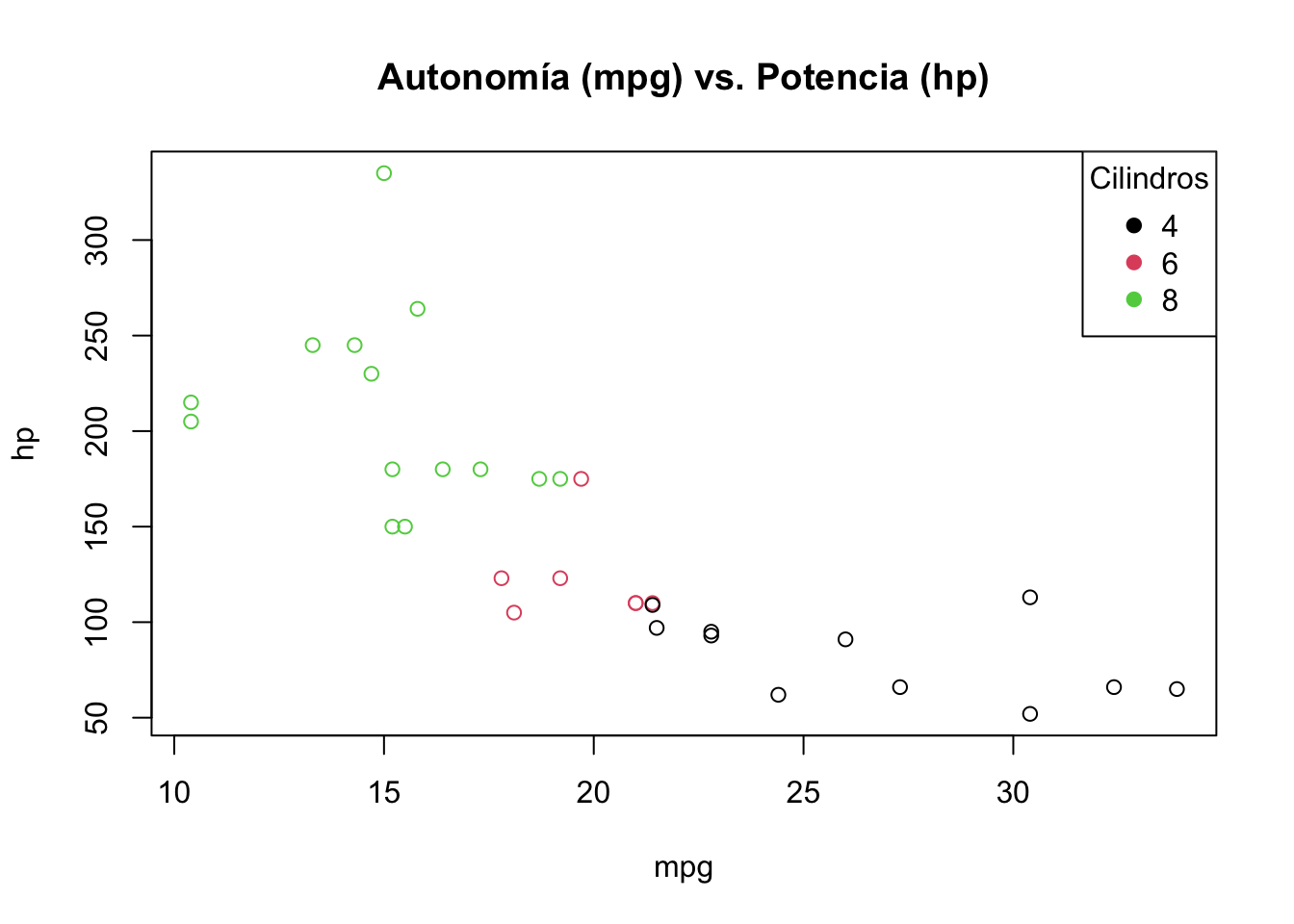
FIGURA 3.2: Gráfico de dispersión condicionado por el número de cilindros.
Se sigue observando una relación inversa entre potencia y autonomía de los automóviles, teniendo en cuenta que los de mayor cilindrada son los que mayor potencia y menor autonomía tienen. A medida que aumente el número de observaciones se tenderá a ver muy lleno el gráfico por lo que convendrá separar en varios gráficos dependiendo del número de cilindros.
3.3 Realización manual
Para separar estos tres gráficos, de manera “manual”, se procedería:
# Disposición de los gráficos
par(mfrow = c(1, 3))
# 4 cilindros
plot(hp ~ mpg, data = data[data$cyl == 4, ], main = "4 cilindros", col = "black")
# 6 cilindros
plot(hp ~ mpg, data = data[data$cyl == 6, ], main = "6 cilindros", col = "red")
# 8 cilindros
plot(hp ~ mpg, data = data[data$cyl == 8, ], main = "8 cilindros", col = "green")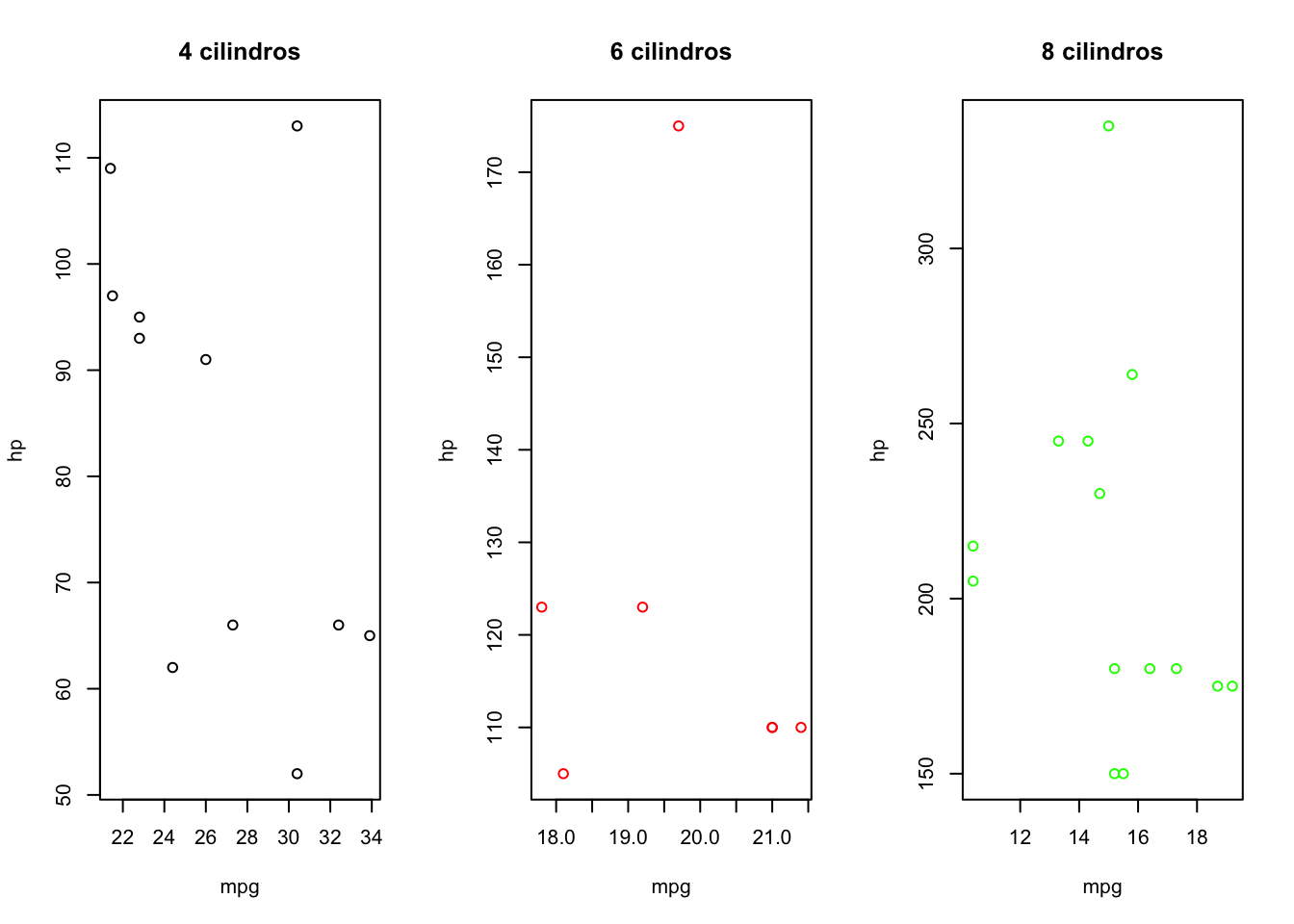
FIGURA 3.3: Gráfico de dispersión condicionado por el número de cilindros (separados).
Conforme aumente el número de categorías, realizar estos gráficos será tedioso y ahí es donde entra en juego el paquete lattice
3.4 Realización automática (lattice)
Véase que el siguiente gráfico realiza la misma tarea con mucho menos código:
# Gráfico por número de cilindros
xyplot(hp ~ mpg | cyl, group = cyl, data = data, scales = "free", aspect = "fill")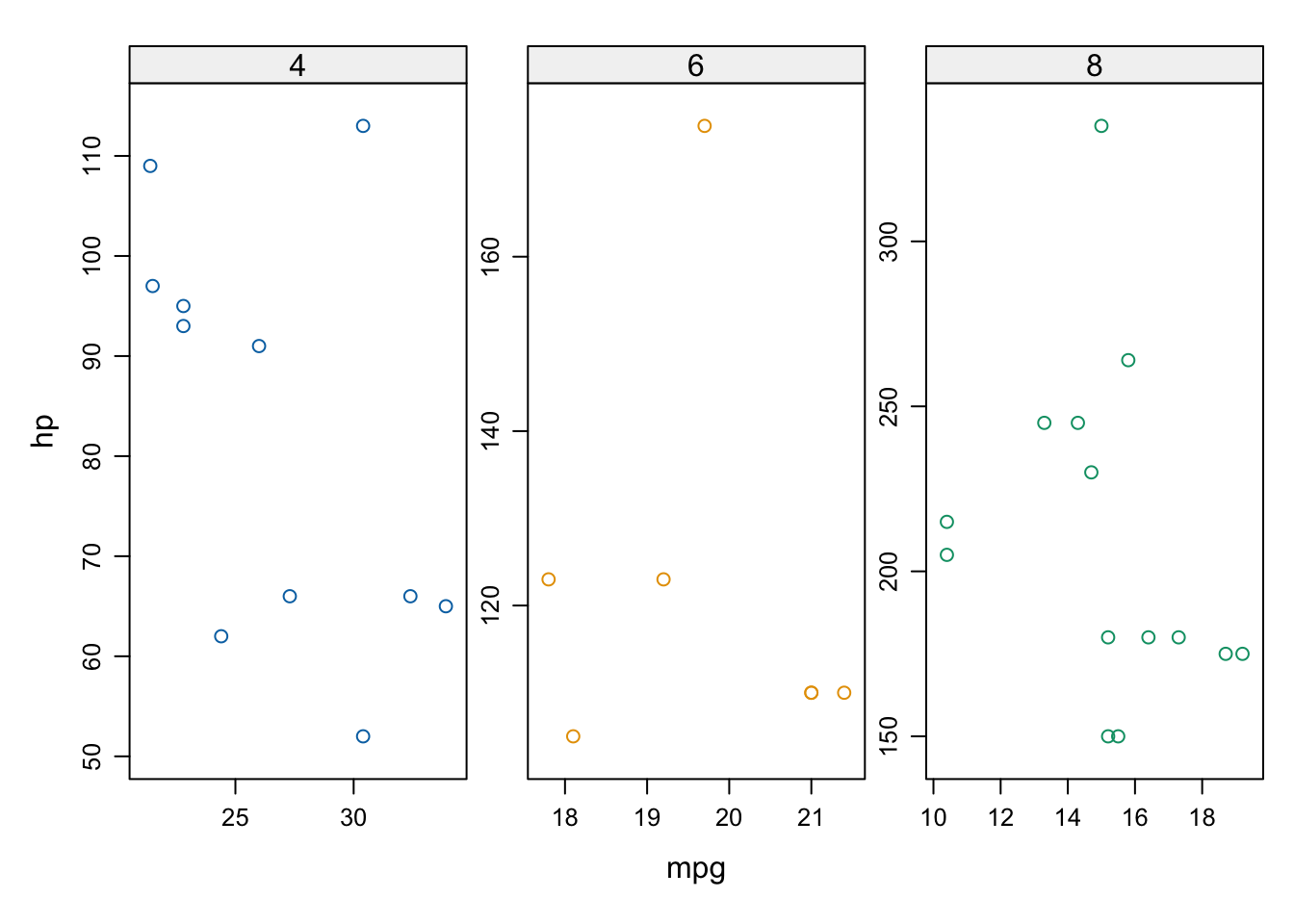
FIGURA 3.4: Gráfico de dispersión con lattice condicionado por el número de cilindros.
Además, se pueden combinar en un miso gráfico al igual que antes (quitando | cyl):
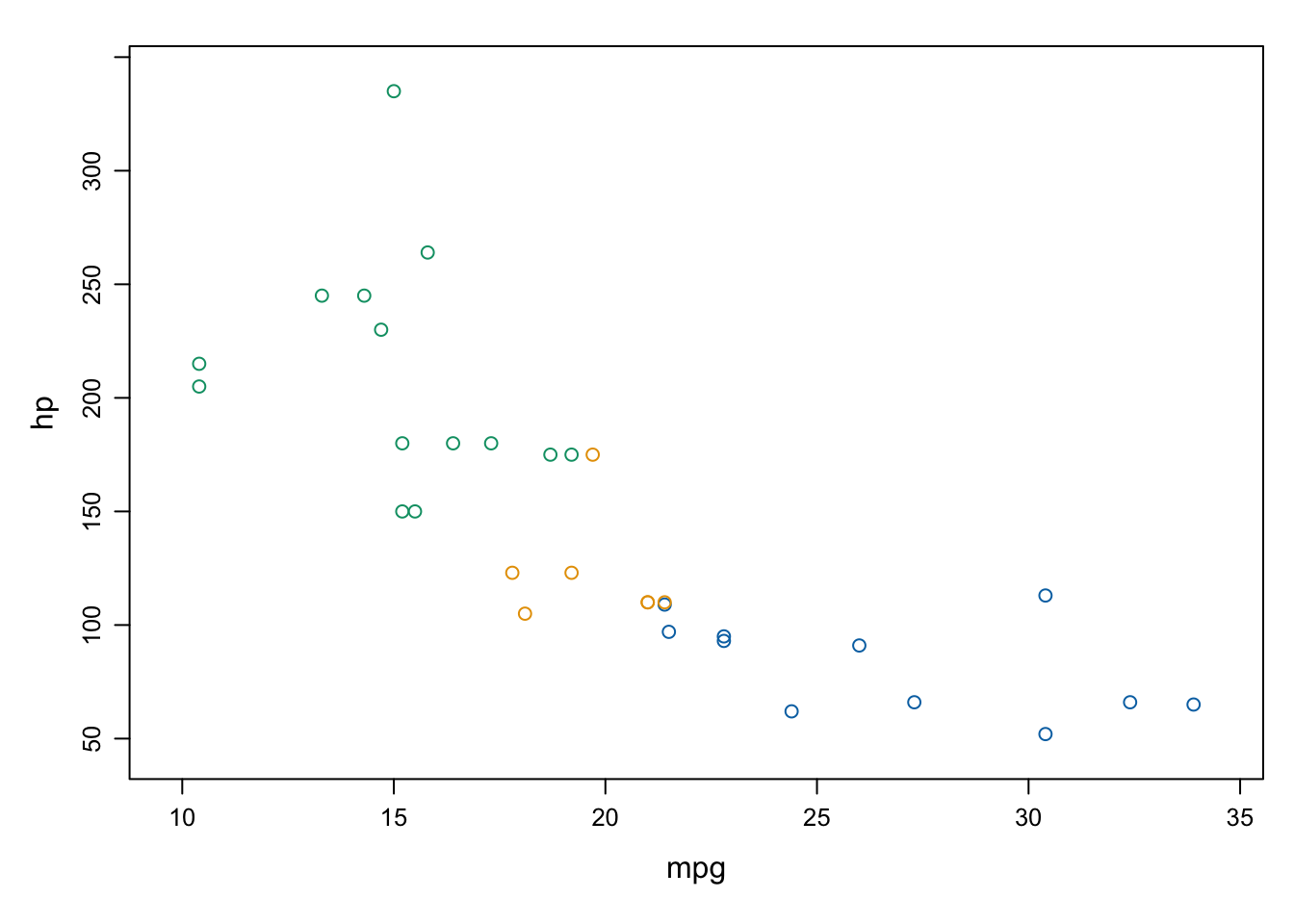
FIGURA 3.5: Gráfico de dispersión con lattice condicionado por el número de cilindros.
Es decir, veamos las forma general de esta función Custom block ver info
donde:
- plot_function: es cualquier función de graficar de
lattice, por ejemplo- xyplot: Diagrama de dispersión
- density.plot: Línea de densidad
- histogram: Histograma
- bwplot: Diagramas de caja
- | g (OPCIONAL): Indica que el gráfico se va a dividir en tantos gráficos como valores tome la variable
data$g. Es decir, nos mostrará el gráfico dey~xpara cada grupo de la variableg - group=g(OPCIONAL): indica que pinte los elementos dibujados agrupando por la variable
g. - data: nombre del conjunto de datos que contiene las variables
x,y,g.
En el siguiente ejemplo, queremos representar la densidad de la autonomía de los vehículos (mpg) distinguiendo el número de cilindros que tienen, por ello:
- Añadir
densityplot(~mpg,data = data)para el gráfico de densidad. - Añadir argumento
| cylpara realizar un gráfico por cada número de cilindros distinto. - Añadir argumento
gorup=cylpara colorear dependiendo del número de cilindros del vehículo.
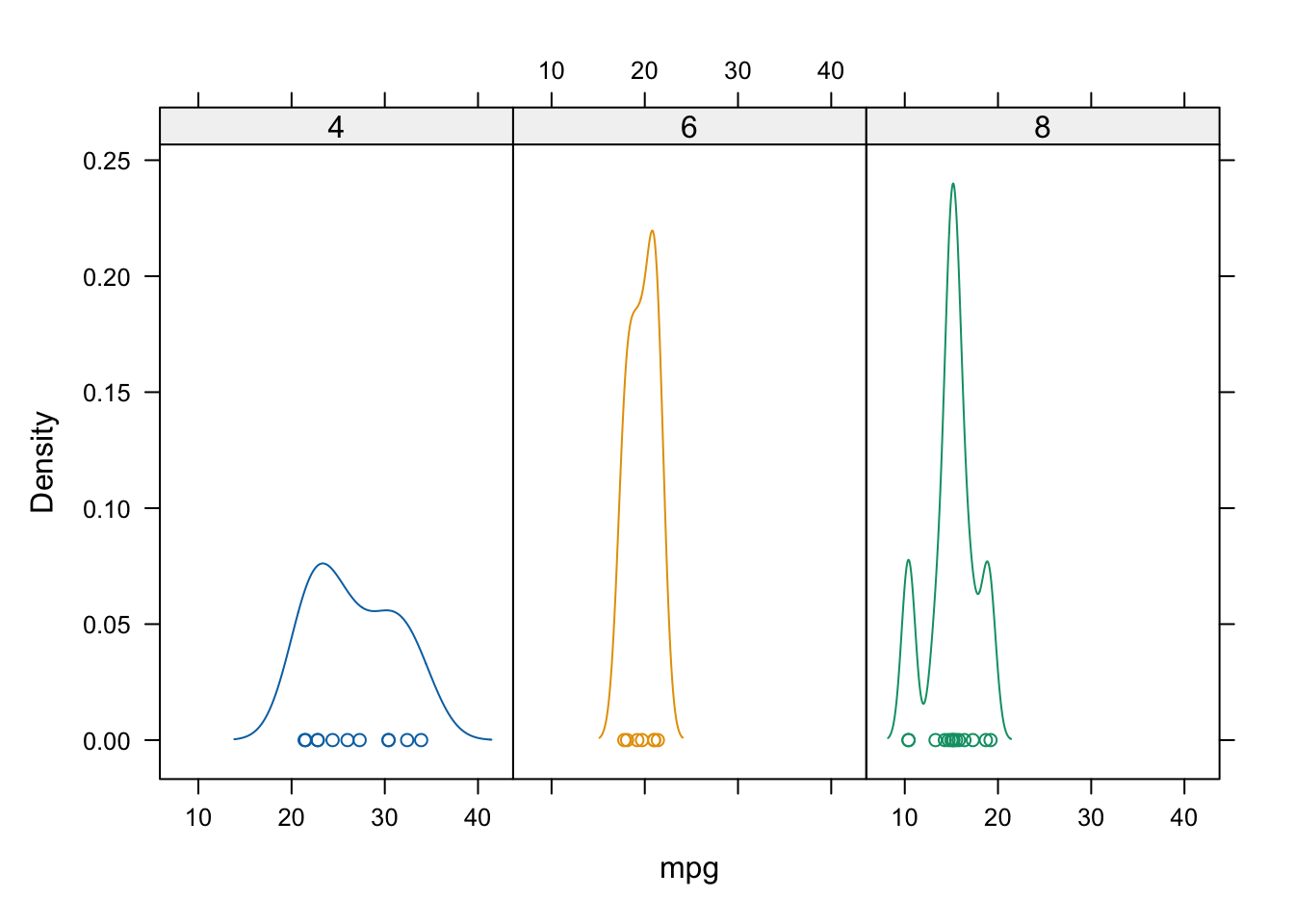
FIGURA 3.6: Densidad de la autonomía condicionada al número de cilindros (en gráficos distintos).
Ahora vamos a mostrarlos todos superpuestos en un mismo gráfico, eliminando el argumento | cyl:
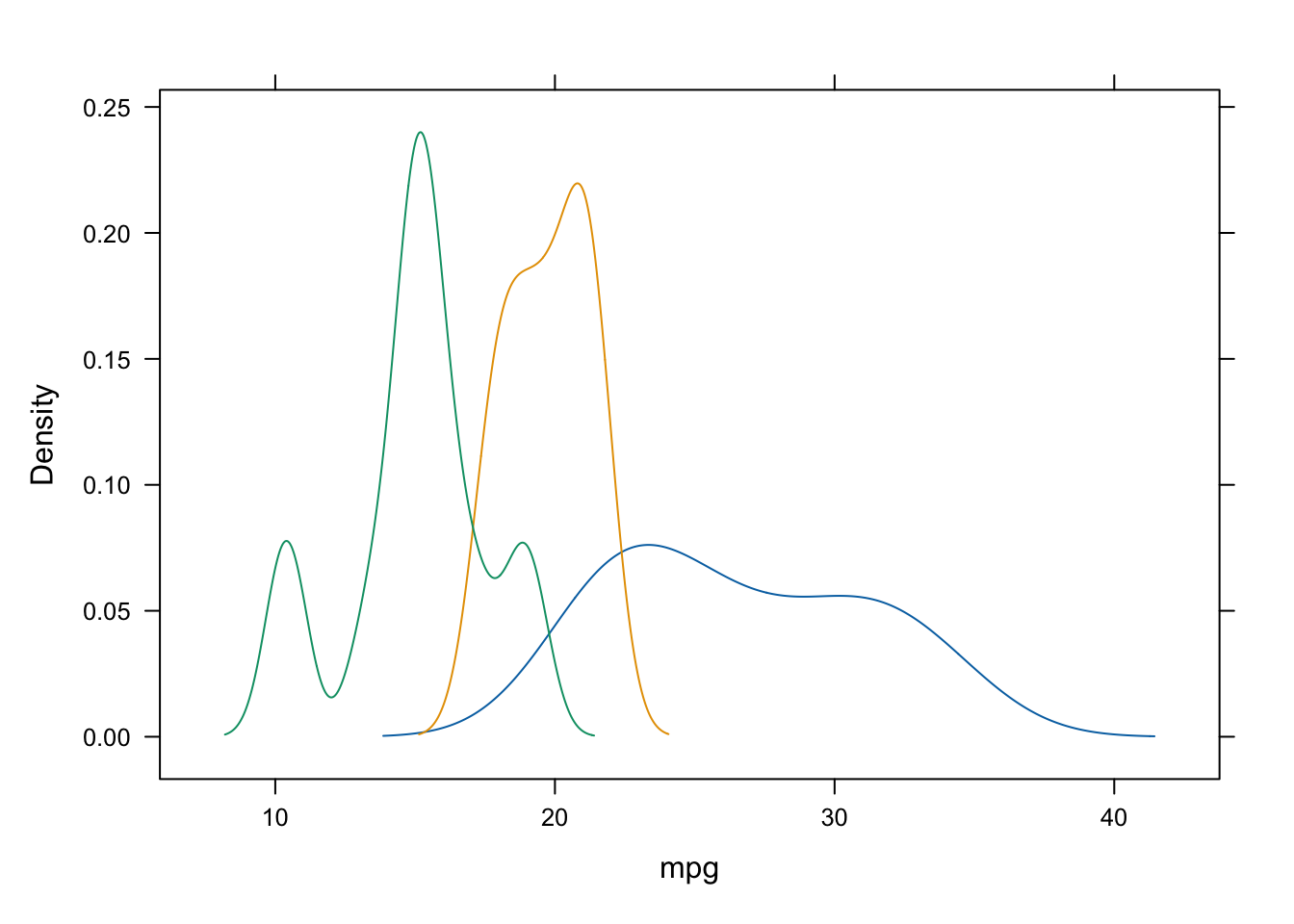
FIGURA 3.7: Densidad de la autonomía condicionada al número de cilindros.
3.5 Más información
Para más información acerca del paquete lattice y casos de uso, consultar:
Sarkar, Deepayan. Lattice: Multivariate Data Visualization with R. Springer, 2008. Este libro proporciona una cobertura completa de las capacidades de
latticepara la visualización de datos multivariantes en R.R Documentation - lattice. Página de documentación que proporciona ejemplos de uso, detalles de funciones y comentarios de la comunidad.
Quick-R: Lattice Graphs Un tutorial práctico que cubre los conceptos básicos de los gráficos
latticey proporciona ejemplos de código.
Un gráfico en trellis es una visualización que presenta múltiples gráficos dispuestos en un conjunto de paneles, permitiendo comparar diferentes subconjuntos de datos de manera eficiente. Cada panel muestra el mismo tipo de gráfico, pero para diferentes segmentos de datos, facilitando la detección de patrones y tendencias en grupos distintos. Véase https://es.wikipedia.org/wiki/Gráfico_de_celosía↩︎